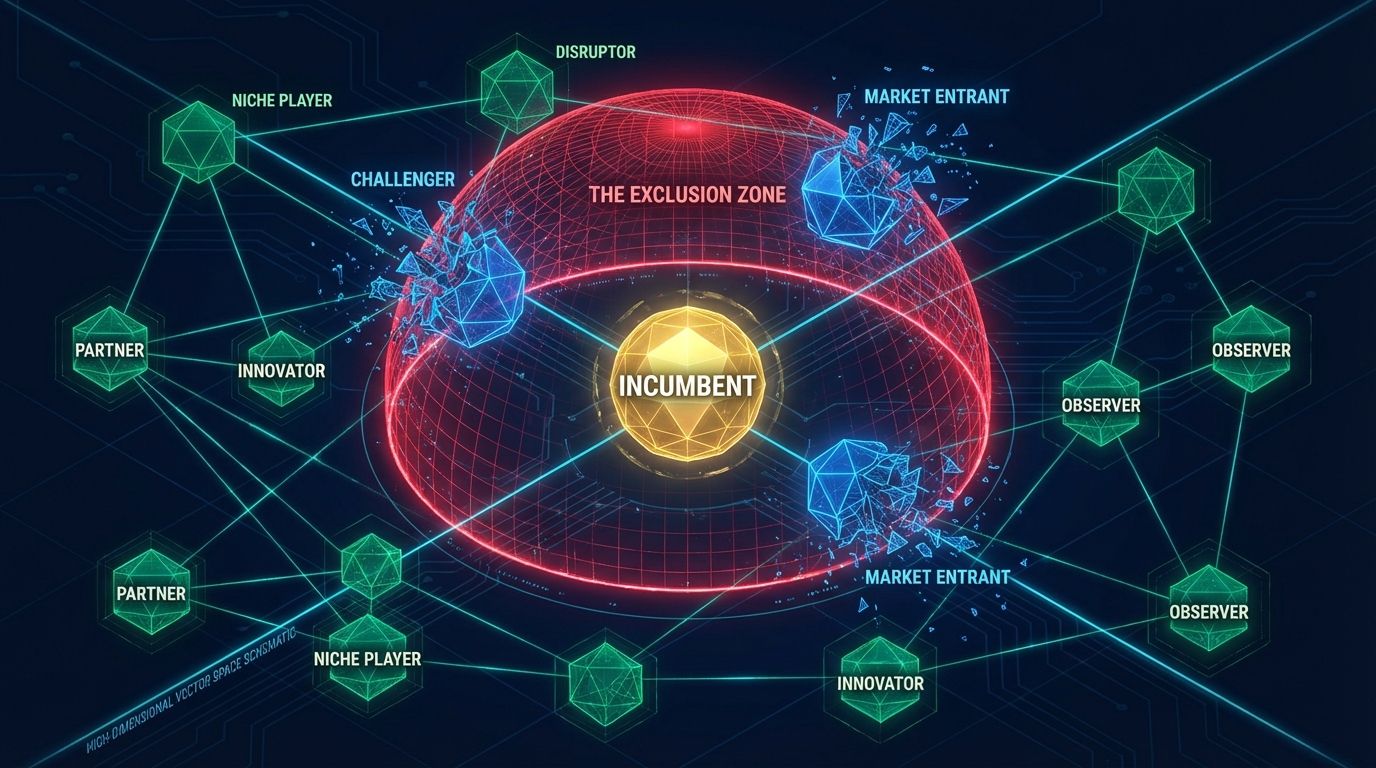
The era of relevance maximization is mathematically over. With Greedy Independent Set Thresholding (GIST), Google pivoted ranking from a sorting problem (who is best?) to a combinatorial optimization problem (which set maximizes geometric diversity?). The result is the Vector Exclusion Zone: once a high-utility incumbent is selected, it projects a semantic radius, and any competing content vector falling inside that radius is not ranked lower, it is thresholded out entirely. To survive, stop optimizing for keyword density and start optimizing for Semantic Orthogonality: you are competing to be the highest-utility node outside the incumbent's radius.
The governing objective is no longer utility alone but a composite function balancing utility against diversity.
Here g(S) is the utility of the selected set and div(S) is its geometric diversity. Maximizing both at once creates a binary failure state for redundant content.
1. The Consensus Trap
For a decade the Skyscraper Technique was the gold standard: find the top result, mimic its structure, cover the same entities, add 10% more depth. Under GIST that's a mathematical liability, a Skyscraper Suicide. By mimicking the incumbent's semantic structure you drive your cosine distance toward zero, and since the incumbent holds the first-mover advantage (higher historical utility), the algorithm selects them and draws the radius. Your content, being semantically proximal, falls inside the exclusion zone, filtered out not for lack of quality but for lack of distinctiveness. You are redundant. The pivot is a move from a topology of "Hills" (vertical accumulation of relevance) to a topology of "Forests" (horizontal ownership of empty vector space): identify the Semantic Centroid of the current results and position your content at a calculated angular distance from it.
2. Forensic Analysis: The Mathematics of Invisibility
GIST solves the "Max-Min Diversification with Monotone Submodular Utility" (MDMS) problem. Because that's NP-hard and can't be solved perfectly at scale, Google uses a greedy approximation with a 1/2 guarantee, which ensures the system never catastrophically fails but also makes the exclusion logic rigid and predictable. If your content structure mirrors the Top 10, your AI readability effectively drops to zero because you're invisible to the selection layer, the same effect observed in the 1,500-site audit where visually rich but semantically generic sites were bypassed by retrieval agents. The algorithm in four steps: sort all candidates by marginal utility, select the highest-value item, exclude any candidate whose distance to a selected item is less than the radius d, then repeat on the next non-excluded item.
3. Information Gain: The Missing Vector
GIST's implications extend beyond the SERP into Retrieval-Augmented Generation. When an LLM constructs an answer it works inside a finite context window; it can't ingest 50 overlapping documents, it retrieves roughly 5, and GIST is the gatekeeper preventing "hallucination via repetition." If the retrieval layer pulls five chunks that all define "photosynthesis," the response is shallow. The effect is a barbell portfolio that hollows out the middle: Slot 1 is max utility (the incumbent, the definition), Slot 2 is max diversity (the orthogonal edge case or counter-argument), and the Death Zone is the "SEO guide" that summarizes Slot 1, carrying moderate utility and near-zero diversity, never cited. To be cited you must provide Net Information Gain: be the missing variable in the equation. In e-commerce, while everyone lists product specs, the missing variable is often real-time inventory, and as the e-commerce AEO guide shows, structuring "Ghost Inventory" data via JSON-LD is one of the few ways to force a diversity selection in shopping queries.
4. Implementation Protocol: Vector Displacement
To survive the era of constrained diversity, operationalize vector displacement across three phases. Phase 1, the vector audit: scrape the Top 3 results for your target query, identify the centroid (the "average argument," e.g. "AI saves time"), then select a narrative more than 0.2 cosine distance away (e.g. "AI creates technical debt"). Phase 2, orthogonal prompting: drive your drafting agents out of the consensus bubble with a prompt like, "Analyze the attached top-ranking articles, identify the core premise they share, then outline an article that accepts that premise but focuses entirely on a consequence, limitation, or edge case those articles ignore; maximize the use of semantic entities that do not appear in the source text." Phase 3, first-mover velocity: GIST is greedy, so it picks the first high-utility item and establishes the radius; monitor "blue ocean" rising-trend queries, publish high-utility content immediately, and once you claim the vector node you set the radius and competitors must work around you. This builds directly on the latent-space mechanics in vector engine optimization.
Is your content inside someone else's exclusion zone?
Free audit. Measures your semantic distance from the incumbents ranking for your query and flags whether you're orthogonal enough to survive GIST selection.
Measure your semantic distance →The contrarian conclusion that overturns the entire content-marketing playbook: "comprehensive" is now a liability, not a virtue. The 5,000-word ultimate guide that covers everything the top result covers, only more thoroughly, is the single most excludable artifact you can publish, because thoroughness drives it toward the centroid and the centroid is already occupied. The winning move in 2026 is to be deliberately incomplete in a direction nobody else has claimed, to own one sharp orthogonal idea rather than to out-cover the incumbent on theirs.
5. Reference Sources
- Fahrbach, M., Ramalingam, S., Zadimoghaddam, M., et al. (2025). GIST: Greedy Independent Set Thresholding for Max-Min Diversification with Submodular Utility. Proceedings of NeurIPS 2025. arXiv:2405.18754
- Website AI Score Research (2026). Case Study: The State of AI Readability. View report
- Website AI Score Engineering (2026). E-Commerce AEO: Optimizing Price & Stock for AI Shopping Agents. View guide
