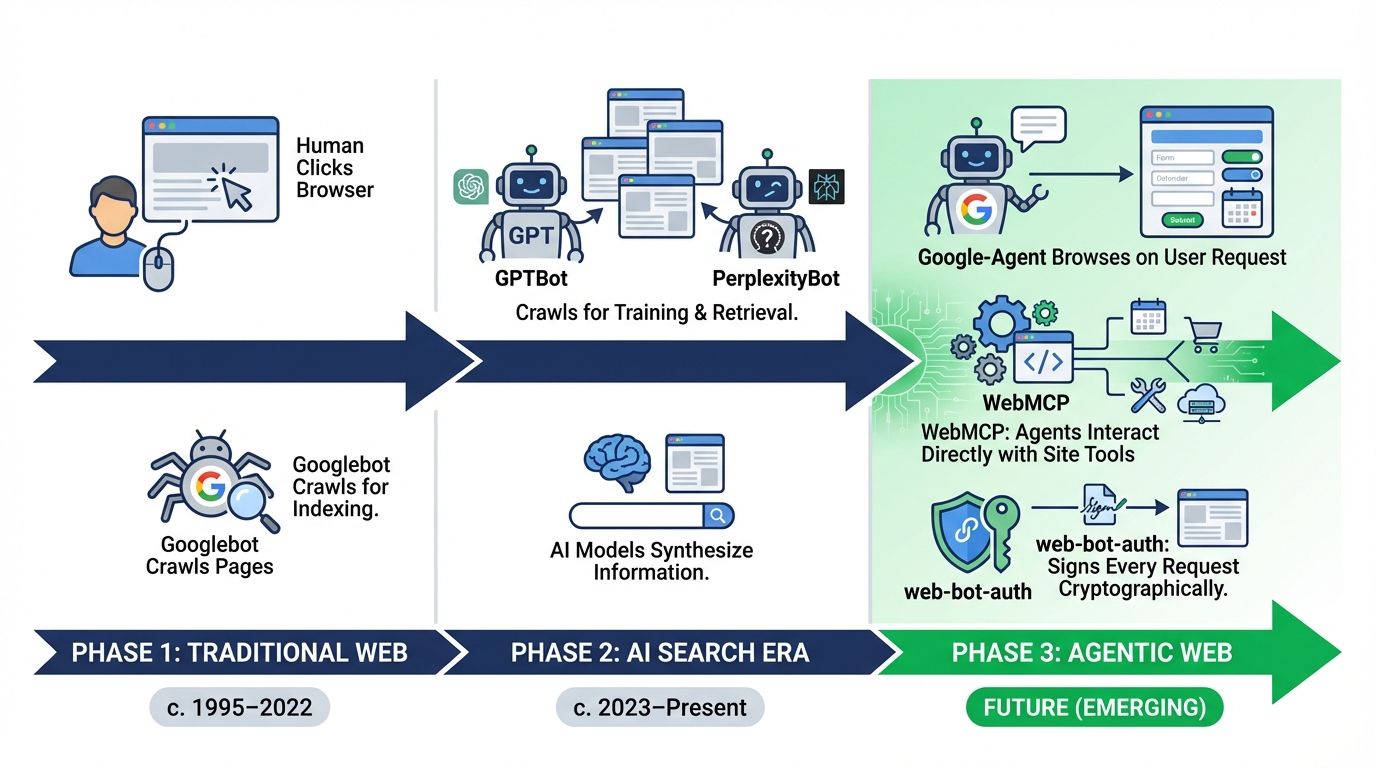
Three developments landed in early 2026 that most SEO coverage missed, and they're three layers of one architectural shift, from a web humans browse and bots crawl to a web where agents act. Google-Agent is the live user-agent for AI agents on Google infrastructure executing tasks on a user's behalf. WebMCP is a Chrome-level protocol letting sites expose structured tool endpoints directly to agents instead of forcing DOM scraping. web-bot-auth is an IETF draft giving servers cryptographic certainty about which agent a request actually came from. This is the complete technical breakdown of all three and exactly what to implement.
1. Google-Agent: The User-Triggered Fetcher You Are Not Logging
On March 20, 2026, Google published a short new entry in its crawler documentation: Google-Agent, the user-agent used when AI agents on Google infrastructure browse the web on a user's behalf. When Project Mariner navigates to your site it doesn't arrive as Googlebot or as a human, it arrives as Google-Agent, and it's doing something categorically different: not indexing, not crawling for training data, but executing tasks. The classification is critical. Autonomous crawlers (Googlebot, Google-Extended) operate on Google's schedule to build its index, respect robots.txt, and are governed by crawl budget. User-triggered fetchers operate on a user's schedule, and because the fetch was initiated by a user action, they generally ignore robots.txt rules, a documented architectural distinction, not a loophole.
Google publishes two variants of the string, both embedding the documentation URL as the canonical verification reference.
Google's own documentation cautions that the user-agent string can be spoofed: anyone can send a request claiming to be Google-Agent, which is why Google also provides the cryptographic verification path (web-bot-auth, Section 3) and why user-agent matching alone is insufficient for access control. Google-Agent uses a distinct IP range set published in user-triggered-agents.json, separate from Googlebot ranges, so existing Googlebot allowlists won't identify it. The only reliable non-cryptographic check is the three-step process used for Googlebot: a reverse DNS lookup on the connecting IP, confirmation that it resolves to a gae.googleusercontent.com or google-proxy hostname, and a forward DNS lookup confirming it resolves back to the original IP.
The practical consequence of the robots.txt carve-out: if your robots.txt blocks User-agent: *, that rule applies to autonomous crawlers but may not prevent Google-Agent from accessing your pages when executing user-initiated tasks. The architectural reason is that a user explicitly asked the agent to visit, and if a human can reach a URL in a browser, blocking the agent acting on their behalf degrades the agent product. This creates a new category of access your existing robots.txt strategy does not govern.
2. WebMCP: The Structured Action Channel That Replaces DOM Scraping
WebMCP is a Chrome-level API that lets websites expose structured tool endpoints directly to AI agents, so instead of an agent parsing your DOM like a human, it gets a defined interface to invoke specific actions with precision. Published as an early preview on February 10, 2026 (developed by André Cipriani Bandarra at Google Chrome), it's available through Chrome's Early Preview Program. Before WebMCP, an agent filling a form had to load and render the DOM, identify form elements by parsing HTML and labels, map intent to fields, execute click/type/submit interactions, and parse confirmation states. That fails two ways: it's slow (each step requires rendering, parsing, and state evaluation) and brittle (any HTML change breaks the agent's interaction, causing silent failures invisible to you and the user). WebMCP replaces this with a direct API contract through two APIs. The Declarative API handles standard interactions defined in HTML forms, analogous to how Schema.org markup works for content: instead of inferring meaning from layout, the agent reads an explicit machine-readable spec. The Imperative API handles complex dynamic interactions requiring JavaScript, providing a programmatic interface the agent calls sequentially for multi-step workflows.
The shift is architectural. For customer support, instead of navigating a form UI, your site exposes a create_support_ticket endpoint the agent calls with structured parameters like {issue_type, severity, description, user_email}, making the interaction deterministic, auditable, and resistant to UI changes. For e-commerce, you expose add_to_cart, get_shipping_options, and initiate_checkout as distinct tools so the agent assembles the transaction through structured calls, the same direction as agentic commerce. WebMCP is not a ranking signal, it's a capability signal: as Google's agentic products route more transactions through the agentic stack, sites exposing WebMCP endpoints get executed while DOM-only sites force slow, error-prone fallback, and agents learn to prefer the path of least friction. The parallel to structured data is direct, a machine-readable price in Product schema wasn't "required" in 2012 but became commercially necessary once Google used it for rich results, and WebMCP is at the same inflection point now.
3. web-bot-auth: Cryptographic Identity for the Request Layer
web-bot-auth (formally "HTTP Message Signatures for automated traffic Architecture," IETF Internet-Draft draft-meunier-web-bot-auth-architecture) lets automated HTTP clients cryptographically sign their outbound requests using asymmetric key pairs, so servers can verify the identity of incoming automated traffic with mathematical certainty. Authored by Thibault Meunier at Cloudflare, it's at version 04 as of October 2025, and Google is actively experimenting with it using the identity https://agent.bot.goog, documented in the Google-Agent spec. It solves three failure modes of current identification: user-agent spoofing (any client can claim any UA, with no cryptographic binding between claim and claimant), IP block ambiguity (cloud IPs have layered ownership, so the binding between an IP and an agent operator is weak and degrades as IPs are reassigned), and shared-secret fragility (an agent sharing a Bearer token with every site faces unmanageable key rotation and total exposure on any compromise). Asymmetric cryptography at the HTTP layer fixes all three.
Each agent has a private signing key and a published public verification key in a discoverable directory. On request, the agent constructs an HTTP Message Signature per RFC 9421 covering at minimum the request's @authority, parameterized with created, expires (max 24 hours recommended), keyid (the key's JWK SHA-256 thumbprint), nonce (anti-replay), and tag fixed to web-bot-auth.
Your server verifies the signature against the agent's published public key; if valid, the request is demonstrably from the agent controlling the corresponding private key, and spoofing is cryptographically infeasible. Agents may also send a Signature-Agent header pointing to their key directory (e.g. Signature-Agent: sig1="https://agent.bot.goog"), letting your server discover the verification key automatically from a standard JWK document even without pre-registration. The server-side validation flow is: parse Signature-Input for the keyid and tag, reject any signature whose tag isn't web-bot-auth, resolve the keyid against the agent's directory, verify the signature with RFC 9421's algorithm, validate that expires is future and created is past, and optionally check the nonce against a local cache to prevent replay.
That is a structural illustration only; production needs a full RFC 9421 library (the http-message-signatures PyPI package, or Cloudflare's reference implementation at github.com/cloudflare/web-bot-auth across TypeScript, Python, PHP, Ruby, Rust, and Go). web-bot-auth creates a new access-control dimension: today your options are binary allow/block by spoofable UA or IP, but with signatures you can build verified-agent tiers, unverified requests get standard anonymous access, verified Google-Agent requests (confirmed via https://agent.bot.goog) get richer agent-optimized responses, verified third-party partner agents get specific API access, and unverifiable requests merely claiming to be agents are treated as anonymous.
4. The Protocol Stack: How the Three Interact
These aren't redundant, they operate at distinct layers. Google-Agent is the identity layer (the "who": what class of visitor is arriving and its behavioral contract). web-bot-auth is the authentication layer (the "prove it": cryptographically verifying the identity claim). WebMCP is the capability layer (the "what": what the agent can do through declared tool endpoints). A complete architecture serves all three.
| Layer | Protocol | Your implementation |
|---|---|---|
| Identity | Google-Agent user-agent | Log and differentiate Google-Agent traffic in your server logs |
| Authentication | web-bot-auth (RFC 9421) | Verify Signature + Signature-Input headers; check the agent.bot.goog directory |
| Capability | WebMCP declarative / imperative API | Expose structured tool endpoints for your key transactional flows |
A site with identity logging but no authentication is vulnerable to spoofing; one with authentication but no capability is verifying agents it can't serve well; one with capability but neither identity nor authentication has no way to audit which agents use its tools.
5. The AEO Audit Implications: New Failure Modes
The agentic web creates five structural failures the existing six-signal framework must account for. No Google-Agent logging: if your logs don't differentiate Google-Agent, you have zero visibility into agentic interaction, fixed with a log filter for compatible; Google-Agent in the UA field. robots.txt misconfiguration for fetchers: because Google-Agent ignores robots.txt, any access control built through it doesn't govern this traffic, so pages that shouldn't be agent-accessible (authenticated areas, private data, rate-limited endpoints) must be protected at the application layer. JavaScript-dependent transactional pages: a fully JS-rendered checkout with no server-side fallback fails for a low-JS agent, the same rendering problem from the empty shell audit applied to transactions, fixed with SSR/SSG or WebMCP. No web-bot-auth verification: without signature checking you can't distinguish a genuine Google-Agent from a spoofed one, making verified-agent policies unenforceable. No WebMCP tool declaration: agents interacting via DOM scraping fail or degrade on complex flows, with no reliable channel for agent-driven transactions.
6. What to Implement First
Immediately: differentiate Google-Agent in your server logs (zero cost, immediate visibility), validate IP ranges against user-triggered-agents.json with the reverse-DNS loop, and protect sensitive paths at the application layer rather than via robots.txt.
Within 30 days: implement web-bot-auth signature verification in your request middleware, initially in logging mode only, verifying signatures and logging the result without acting on failures, to build a baseline of what percentage of claimed agent traffic is actually verified.
Also add WebMCP declarative forms to lead-capture pages (the lowest-effort, highest-near-term-relevance WebMCP move as Google-Agent begins submitting forms). Medium-term, as WebMCP reaches general availability: implement the imperative API for checkout and booking flows (join Chrome's Early Preview Program at developer.chrome.com/docs/ai/join-epp), and implement tiered access control serving verified agents richer responses while rate-limiting unverifiable ones.
7. The Updated llms.txt for Agent-Aware Sites
Because Google-Agent generally ignores robots.txt, the standard llms.txt + robots.txt guidance needs a new layer. Your llms.txt stays relevant for training crawlers and RAG retrieval that do read it, but it doesn't govern user-triggered agent behavior. A forward-compatible pattern extends it to advertise agent readiness.
This extension isn't an official standard, it's a forward-compatible pattern communicating your agent readiness to any system that reads it.
8. The Three Questions Your Site Must Answer
The agentic web is not a future state: Google-Agent is documented and live, WebMCP is in early preview with production planned, web-bot-auth is at draft 04 with Google experimenting on agent.bot.goog. Three questions decide whether your site functions in it. Can agents identify themselves when they visit? If you aren't logging Google-Agent separately and verifying against the published IP ranges, you have no visibility, so implement log differentiation now. Can you verify an agent is who it claims to be? Without web-bot-auth verification any identity claim is unverifiable, so implement RFC 9421 checking in logging mode. Can agents interact with your tools directly? If your flows require DOM scraping, agents fail silently at scale, so WebMCP declarative forms for lead capture are implementable today and the imperative API is the medium-term mandate. This is the agentic extension of everything in the scoring signal guide and the inference economy roadmap.
Is your site ready for the agentic web?
Free audit. Start with the rendering and crawl-access signals that decide whether a user-triggered agent can complete a task on your site at all.
Audit your agent readiness →The contrarian point that separates this shift from every SEO panic before it: the agentic web won't punish you in a way you can see. There's no ranking drop to diagnose, no deindexed page to recover, no traffic graph that falls off a cliff. The failure mode is a user who asked an AI to book, buy, or contact through your site and silently received an error, then went to a competitor whose checkout the agent could actually drive, and you will never appear in any report as the cause. For twenty years SEO failures were visible because humans bounced and analytics recorded it. Agentic failures are invisible because the human never arrives to bounce. The sites that win the next decade aren't the ones that rank best, they're the ones an agent can finish a job on without a human ever watching.
Reference Sources
- Google Crawling Documentation, Google-Agent: official user-agent spec, IP ranges, and verification guidance (updated 2026-03-20). Google Developers
- Chrome for Developers, WebMCP Early Preview: official announcement and Early Preview Program registration (2026-02-10). developer.chrome.com
- IETF Internet-Draft, web-bot-auth (draft-meunier-web-bot-auth-architecture-04): full specification. Author: Thibault Meunier (Cloudflare). datatracker.ietf.org
- RFC 9421, HTTP Message Signatures: the underlying standard web-bot-auth builds on. rfc-editor.org
- Google Developers Blog: developer's guide to AI agent protocols (MCP, A2A, UCP, A2UI, AG-UI), 2026-03-18. developers.googleblog.com
- Google DeepMind, Project Mariner: the agentic browsing system using the Google-Agent UA. deepmind.google
- Cloudflare web-bot-auth Reference Implementation: open-source clients and servers across six languages. github.com/cloudflare/web-bot-auth
- Google User-Triggered Agents IP Range File: machine-readable JSON of Google-Agent IP ranges. user-triggered-agents.json
- Website AI Score, Rendering Signal: how the empty-shell failure applies to agent-facing content. View article
- Website AI Score, Crawl Access Signal: robots.txt and llms.txt audit methodology. View article
