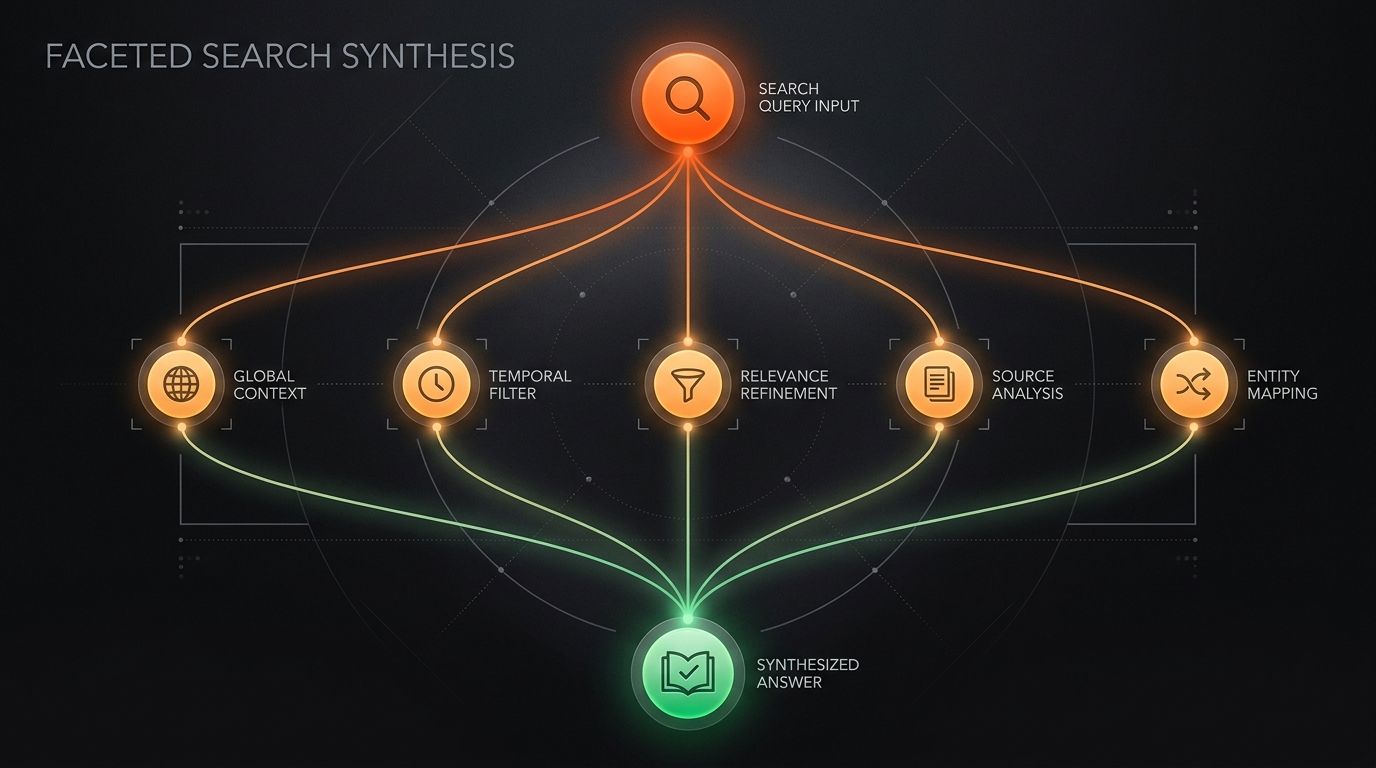
When a user asks an AI engine one question, the engine usually does not run one search. It runs three to eight. This is query fan-out: the model decomposes a single prompt into multiple sub-queries, retrieves for each, and synthesizes one answer from the combined results. The consequence for your content is that you are not competing for the user's literal phrase. You are competing for a set of sub-queries the engine generated and you will never see directly. The pages that win are the ones that answer the decomposition, not the prompt. This is how fan-out works, how to infer the sub-queries you cannot observe, and how to structure content to catch them.
Here is a thing that breaks most people's mental model of AI search. You type "what's the best CRM for a small agency" into Perplexity. You imagine the engine runs that search, reads the top results, and writes an answer. That is not what happens. The engine reads your prompt and silently expands it into a fan of narrower questions: best CRM small business, CRM pricing comparison, CRM for agencies specifically, CRM with project management, and a few more. It retrieves for each of those separately, gathers a pool of candidate passages, and synthesizes one answer from the pool. The thing you typed was the trigger. The things it actually searched for were generated.
I spent years watching retrieval logs, and the gap between "the query the user typed" and "the queries the system ran" is the single most underappreciated mechanic in AI search. If you optimize for the literal prompt, you are optimizing for a query the engine may never actually run. If you optimize for the decomposition, you catch the engine where it is actually looking. Almost nobody is doing the second thing, which makes it a rare open lane.
Why engines fan out instead of searching once
Fan-out exists because a single retrieval against a complex prompt returns mush. "Best CRM for a small agency" has at least four buried requirements: it must be a CRM, it must suit small organizations, it must fit agency workflows, and "best" implies comparison. A single search against that full string returns pages that match the phrase loosely but answer none of the requirements precisely. By decomposing, the engine can retrieve a precise set for each requirement and assemble an answer that actually addresses all of them.
This is the same instinct behind the layered way an LLM picks sources. Fan-out happens at the very top of that stack, before retrieval even runs. The decomposition step decides what gets searched, which means it decides which of your pages even enters the candidate pool. If your content does not map to any of the generated sub-queries, you are filtered out before the citation mechanics ever look at you.
The number of sub-queries scales with prompt complexity. A simple factual prompt might fan out to two. A comparison or recommendation prompt commonly hits five to eight. Conversational follow-ups generate fresh fans that inherit context from earlier turns, which is why the second question in a session can surface completely different sources than the first.
The engines also fan out differently from each other, which is why the same prompt cites different sources across ChatGPT, Perplexity, and Gemini. Each engine's decomposition reflects its own retrieval design. Perplexity leans toward broad coverage, generating wider fans that pull more distinct sources. ChatGPT's browse mode tends toward fewer, more targeted sub-queries. Gemini, sitting on Google's infrastructure, decomposes in a way that overlaps more with classical search intent clustering. The practical effect is that winning one engine does not mean winning the others, because each one fanned your prompt into a different set of questions.
The implication: you compete for queries you cannot see
Classical SEO gave you the query. You knew the keyword, you could see it in Search Console, you optimized the page for it. Fan-out removes that visibility. The sub-queries are generated inside the model at inference time and never appear in any tool you have access to. You cannot pull a report of "the sub-queries Perplexity generated from prompts about your category." They are ephemeral and invisible.
This breaks the keyword-targeting model entirely. You are no longer trying to rank for a phrase. You are trying to be the cleanest available answer to whichever sub-queries your category naturally decomposes into. When you inspect Perplexity's view-sources panel, you can sometimes see the fan in action as different cited sources line up against different facets of the answer, each one having won a different sub-query.
How to infer the sub-queries you cannot observe
You cannot see the sub-queries directly, but you can reconstruct them, because the decomposition is not random. It follows the implicit requirements buried in the prompt. Take your category's most important prompts and decompose them yourself the way the model would.
Start with the head prompt a buyer would actually type. Then ask: what are the hidden requirements inside this? Each requirement is a probable sub-query. "Best project management tool for remote teams" decomposes into project management tool, tool for remote teams, comparison of options, probably pricing, probably integrations. Write the fan out by hand. Do it for your ten most valuable prompts and you will have fifty to eighty inferred sub-queries, and the patterns across them will show you the facets your content needs to cover cleanly.
The validation move is to actually run those head prompts through ChatGPT, Claude, Gemini, and Perplexity and read which sources they cite. The cited sources reveal which sub-queries got answered and by whom. If a competitor is cited for the "pricing comparison" facet and you are not, you just found a sub-query you are losing. This is reconstruction by observation, and it is the closest you can get to seeing the invisible fan.
Work one example all the way through so the method is concrete. Take "best email marketing platform for ecommerce." Decompose by hand: email marketing platform (category), platform for ecommerce specifically (vertical fit), comparison of leading options (the "best" requirement), pricing across tiers (implied), integrations with major store platforms (implied for ecommerce), deliverability and automation features (the buyer's real concern). That is six inferred sub-queries from one prompt. Now run the prompt through all four engines and note which of your pages, if any, gets cited and against which facet. You will typically find you win one or two facets and lose the rest, and the lost facets are exactly the sections your content either lacks or buries. The gap between your six inferred sub-queries and the facets you actually win is your content roadmap for that prompt, and it is far more precise than any keyword tool would give you, because it is derived from how the engines actually decompose rather than from search volume.
The one signal you can capture directly: server-side detection
There is one place the fan becomes partially visible: your own server logs. When an AI engine fans out and retrieves, several of those sub-query retrievals can hit your site as separate requests from the engine's crawler, sometimes within the same few seconds, each fetching a different page. If you log by user agent and cluster requests by time window, you can see the engine pulling multiple pages of yours for what was almost certainly a single user prompt.
This will not give you the sub-query text. It will give you something almost as useful: which of your pages the engine considered relevant enough to fetch together for a single answer. If three of your pages get pulled in one burst, the engine sees them as covering related facets of one question, which tells you your topical clustering is working. If only one page ever gets pulled while competitors get several, your coverage of the fan is thin. This pairs directly with the broader problem of tracking AI engine activity in your analytics, where the standard tools hide most of what is actually happening.
How to structure content for the fan
The practical takeaway changes how you build pages. Instead of one page targeting one head keyword, you want coverage across the decomposition. That does not mean a thin page per sub-query. It means a strong page whose sections each answer one facet cleanly enough to be retrieved and quoted in isolation. A section that answers "CRM pricing for small teams" as a self-contained block can win that sub-query even when the page's headline is about something broader.
This is where the extractability signals that determine whether a passage gets cited matter most. Each section needs to stand alone. If understanding your pricing section requires reading the three paragraphs above it, the engine cannot lift it cleanly for the pricing sub-query, and it loses to a competitor whose pricing answer is self-contained. The fan rewards modular, atomic sections far more than it rewards one long flowing argument.
The contrarian conclusion: long, comprehensive pages can lose to focused ones, not because length hurts, but because a sprawling page rarely answers any single sub-query as cleanly as a tight page built around that facet. The engine is not grading your page. It is grading individual passages against individual sub-queries you never see. Build for the fan, not the prompt.
Sources
- OpenAI, ChatGPT search: documentation on multi-step retrieval and how browse decomposes queries. help.openai.com
- Perplexity: engineering and product material on how the answer engine retrieves and assembles sources. perplexity.ai/hub/blog
- Anthropic, Claude web search: how Claude runs and combines multiple searches per request. docs.claude.com
- Website AI Score, the Citation Stack: where fan-out sits in the broader source-selection pipeline. View article
- Website AI Score, AEO scoring signals: the extractability signals that decide whether a passage wins a sub-query. View article
