DIRECT ANSWER
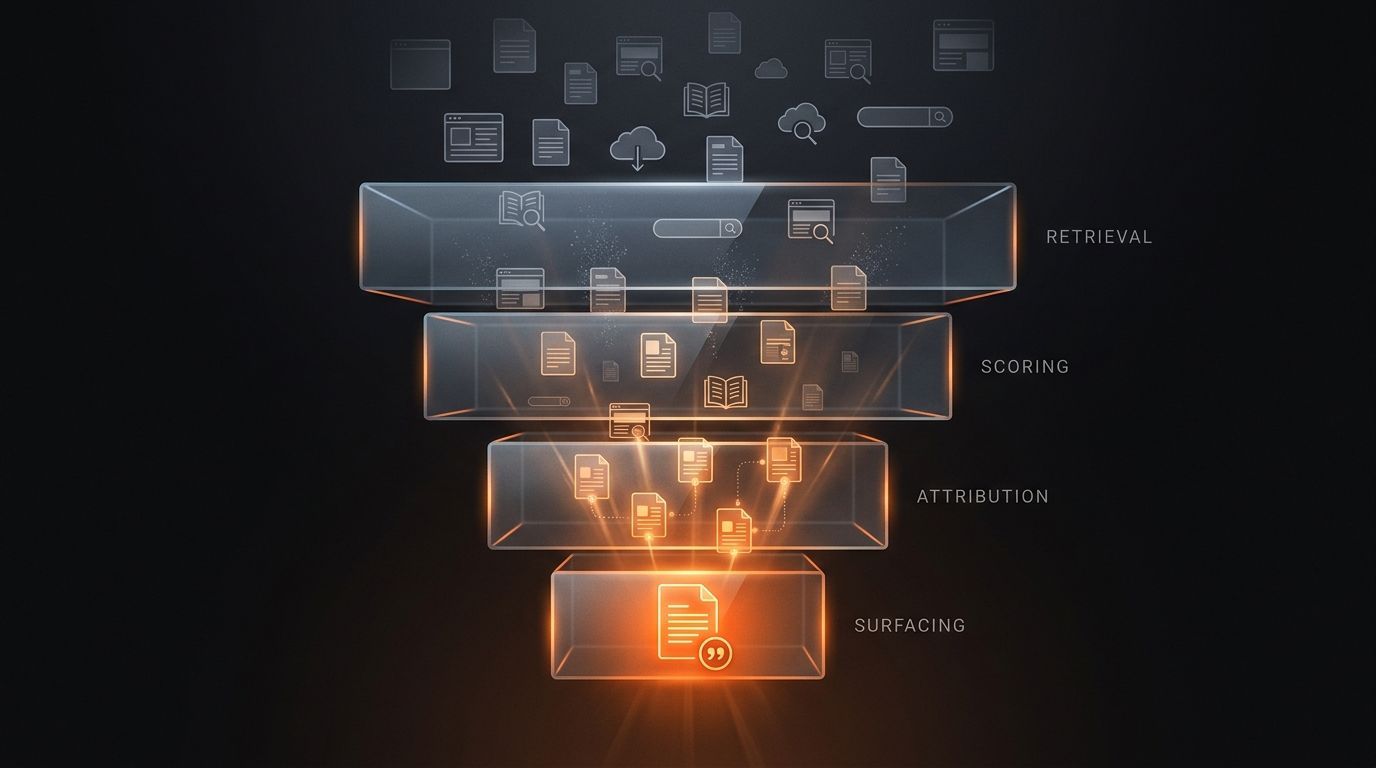
An LLM picks sources through four sequential layers, not one ranking function. Retrieval pulls candidate documents from the index. Scoring ranks them against the query embedding and a relevance model. Attribution selects which of the ranked candidates actually gets quoted in the answer. Surfacing decides whether the citation appears inline, in a footnote, in a side panel, or not at all. A page can win Retrieval and lose Surfacing. Most pages losing AI traffic in 2026 are losing at layers three and four, not layer one. This is what each layer actually does and what determines who wins it.
The conventional model of "how AI search works" collapses four distinct mechanisms into one ranking function and then gets confused about why a page that ranks fifth in a Google search disappears entirely from a Perplexity citation list. The two systems don't share a ranking function, and Perplexity itself doesn't have one ranking function. It has a pipeline. Each stage applies different criteria, and a candidate document gets eliminated at a different stage in different sessions. Debugging citation behavior in production for the last four years taught me that the question "why didn't my page get cited" almost never has a Retrieval answer, even though that's where most people look first.
The Citation Stack is a four-layer model of how a retrieval-augmented LLM converts a user query into an answer with sources. The layers run sequentially, and a document has to survive all four to appear in the final answer. Understanding which layer is filtering you out is the prerequisite to fixing anything.
Layer 1: Retrieval
Retrieval is the first filter and the only layer where the question is mechanical: can the system actually find your document at all. The retrieval stage of a RAG pipeline pulls candidate documents from one or more sources. For ChatGPT browse and Perplexity that source is a search index built from a live crawl. For Claude with web search it's a similar live retrieval through a partner API. For an LLM answering from training data alone the "retrieval" is internal: the model surfaces a representation of your domain from its weights without ever touching the open web during the session.
The retrieval stage typically pulls hundreds to a few thousand candidate documents. The filter is broad on purpose. At this layer, the system is asking: does any document in my index contain content that could plausibly be relevant to the query embedding? If your page is in the index and contains content that vector-matches the query, you survive Retrieval. If your page renders as an empty shell because the content loads via client-side JavaScript that the crawler doesn't execute, you don't. Most Retrieval failures are infrastructure failures, not content failures. The page exists, the content exists, but the crawler couldn't see the content at fetch time. The 200ms Trap walks through the empty-shell failure in detail, and it's the single most common Layer 1 failure I see in audits.
Retrieval is solvable. Render server-side or pre-render the critical content. Submit a sitemap. Don't block AI crawlers in robots.txt (a surprising number of sites still do this without realizing). If your page survives Retrieval, you're in the candidate pool. Surviving the candidate pool is the easy part.
Layer 2: Scoring
Scoring is where most SEO instincts go wrong, because Scoring is not ranking in the Google sense. It's a relevance function over a vector space. The candidates from Retrieval get scored against the query in three different ways simultaneously: semantic similarity via embedding distance, lexical match via BM25 or a similar bag-of-words signal, and topical authority via an entity-strength signal that varies by engine. The candidates are then re-ranked into a much smaller set, usually somewhere between ten and fifty documents.
Two things matter at this layer that don't matter at Layer 1. The first is topical clustering. A page that's nominally about your target query but surrounded by off-topic content on the same domain scores worse than a page on a thin domain that's tightly focused. The vector model can read the surrounding context and it dilutes the page. The second is entity match. If the query mentions a brand or a concept, the engine is checking whether your domain is recognized as an entity associated with that brand or concept. An entity home page is what produces that recognition, and a page without one will lose Layer 2 to a competitor's page that has one even if the competitor's content is weaker on the actual query.
The contrarian point: Layer 2 rewards focus over depth. A 1,200-word page on a single tight concept, embedded in a site that's also focused, beats a 4,000-word page on the same concept embedded in a site that covers six other things. The vector model is not impressed by your word count.
Layer 3: Attribution
Attribution is the layer almost nobody talks about and it's where most pages losing AI traffic in 2026 are actually losing. After Scoring produces its ranked candidate set, the LLM has to do something different from ranking: it has to pick passages to quote. The Attribution stage selects three to eight passages from the top candidates and assigns them to specific claims in the generated answer. A page can be ranked third in Scoring and not have a single passage selected for Attribution, while a page ranked eighth gets two passages quoted. This is the gap that breaks the intuition of "I rank well, why don't I get cited."
Three things determine Attribution. Direct-answer structure: a paragraph that opens with a clear factual claim attached to a specific entity or number gets quoted; a paragraph that builds slowly to a conclusion doesn't. Token efficiency: the token tax penalty on HTML tables versus markdown applies here, because the LLM is choosing passages it can quote within a tight token budget, and a passage that takes 200 tokens to express a 50-token fact will lose to a leaner alternative. Extractability: the passage must stand alone. If the meaning depends on the surrounding paragraph, the LLM can't quote it in isolation.
Attribution is also where the Princeton GEO research surfaces. The team behind the GEO paper from KDD 2024 measured which content interventions actually raise citation rate in generative engines, and the strongest signals were authority-anchored claims (a citation or statistic backing the claim) and quotation-style direct phrasing. Both are Attribution-layer optimizations. Neither helps Retrieval or Scoring much, but both move citation rate substantially.
Layer 4: Surfacing
Surfacing is the final filter and it's invisible from most analytics. The Attribution stage selected three to eight passages and tied them to claims. Surfacing decides which of those tied passages actually appears as a visible citation to the user. Some appear inline as numbered markers next to the claim. Some appear as a footnote at the bottom. Some appear in a side panel of "sources used." Some are used by the model to generate the answer but never displayed to the user at all, which is the cruelest outcome: your content shaped the answer, but the user never sees your name.
Surfacing decisions are driven by source authority and recency. The engines apply a final pass that asks: of the eight passages I'm using, which three or four am I willing to put my reputation behind by showing the user? A passage from a domain the engine recognizes as authoritative on this topic surfaces. A passage from an unknown domain might still inform the answer but won't appear as a visible citation. Share of Model is the metric that captures this, and it's distinct from anything in classical SEO because it tracks visible citation rate per engine rather than ranking position.
Surfacing is where the engines also apply diversity logic. If two of the eight Attribution passages are from the same domain, only one usually surfaces. If three of the eight are all from one publishing network, the engine may surface only one to avoid making the answer look like an ad. This is why a single domain rarely captures more than one visible citation slot per AI answer, even when it deserves several.
What it means in practice
Most pages losing AI traffic are not losing at Layer 1. The infrastructure is fine, the crawler is reaching the page, the index has it. They're losing at Layer 3 or Layer 4. The page is ranked, the page is relevant, the engine is reading it, and the engine is choosing not to quote it visibly because the structure makes it hard to extract a clean passage, or because the domain isn't recognized as authoritative enough to surface.
The fix sequence is the opposite of intuition. Don't start with "more content." Start with an audit that tells you which layer you're failing, then fix that layer specifically. The full AEO scoring signal guide maps every input signal to its corresponding layer, and the signal-to-layer mapping is what makes the difference between an audit that finds 30 issues and an audit that finds the three issues actually costing you citations.
The Citation Stack is not a metaphor. It's a sequential pipeline, and the layer you're losing is diagnosable from the failure signature. Build for all four. Most of your competitors are still building for one.
Sources
- Princeton, "GEO: Generative Engine Optimization": the KDD 2024 paper measuring which content interventions raise visibility in generative engines. arxiv.org/abs/2311.09735
- Anthropic, Claude search and browse documentation: the retrieval and citation mechanics behind Claude's web tool. docs.claude.com
- OpenAI, ChatGPT search documentation: how ChatGPT's browse mode retrieves and attributes sources. help.openai.com
- Perplexity Engineering, on citation and ranking: the public technical posts on how the Perplexity answer engine ranks and quotes sources. perplexity.ai/hub/blog
- Website AI Score, Audit Engine: how Website AI Score maps each layer's failure modes to specific signals. View article
- Website AI Score, AEO Scoring Signals: the complete signal-to-layer mapping for the full scoring engine. View article
