Classification: forensic audit / AEO architecture. Subject: B2B SaaS platform, category AI tooling.
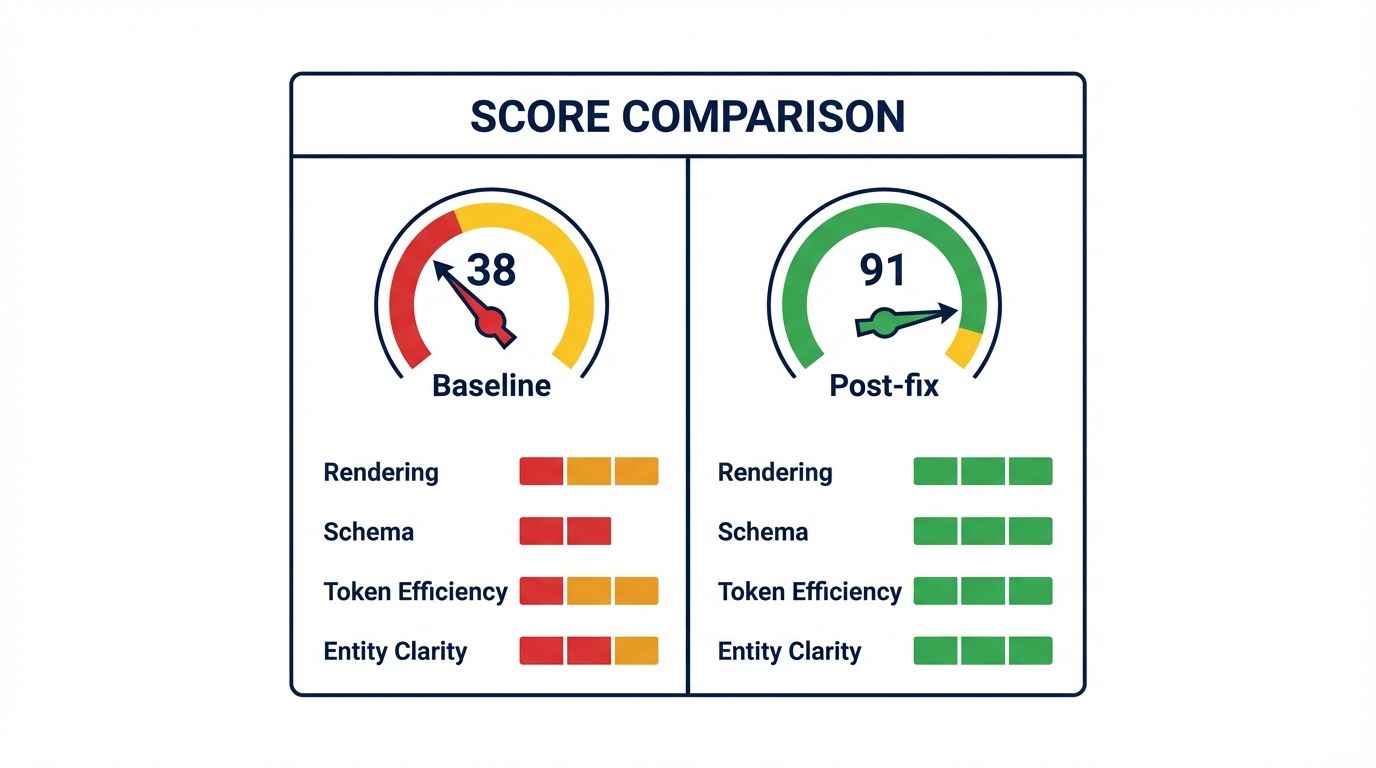
The audit request came in at a score of 38. The site wasn't technically broken: it ranked on page one for several category keywords and had a live blog, product page, pricing page, and active customers. But searching their category in ChatGPT surfaced three competitors, searching their own brand returned a description three versions out of date and missing their primary feature, and a Perplexity query about tools worth considering cited a content aggregator, not the actual product. Score 38, firmly in the Invisible tier. This is how it reached 91.
1. Baseline Audit: The Four Failures
The initial audit identified four signal failures, two in the Fail tier and two in Warn, which together explained why the content was inaccessible to most AI retrieval pipelines despite being crawlable by Google. Rendering: Fail (14/100). The site was a React SPA with client-side rendering, and the raw HTML delivered to non-JS crawlers was a single <div></div>; every heading, description, and pricing table existed only in the post-hydration DOM, so from the perspective of Common Crawl, GPTBot, and every latency-budgeted retrieval agent, the site was a blank white page. Schema Validity: Fail (22/100). A single Organization block with only name, url, and logo; no product, service, or article schema and no sameAs references, so the AI had no machine-readable data on what the product did or cost, and everything had to be inferred from text it couldn't access. Token Efficiency: Warn (58/100). Even where text was eventually reachable through Google's JS rendering, the homepage delivered 94KB of bundle overhead before the value proposition, and the 100-Token Rule failed because the first readable content was the navigation menu. Entity Clarity: Warn (51/100). A common two-word brand name with no disambiguation, an absent sameAs array, an unreferenced LinkedIn page, and no Wikidata entry left the AI only the domain name to resolve the entity.
2. Priority Stack: Sequencing the Fixes
With four failing signals the sequencing decision was critical, because the wrong order wastes effort. Rendering went first (priority 1): rendering failures block everything downstream, since schema on a page delivering an empty shell is never evaluated and token-efficiency gains on an uncrawlable page are irrelevant. Schema went second (priority 2): once the page is crawlable, structured data is the single highest-impact fix for citation quality. Entity clarity and token efficiency ran in parallel as priority 3 in the same sprint after the first two validated, since entity clarity required external profile creation on its own timeline and token efficiency was a template-level change. This is the discipline from the validation loop, applied at the page level.
3. Implementation and Validation
Fix 1, rendering (Next.js SSR migration): the React SPA was migrated to Next.js with getServerSideProps on all primary landing pages (product, pricing, homepage prioritized) and getStaticProps for blog posts. Re-audit: rendering moved 14 → 88, the content delta between the JS and no-JS crawl collapsing from 94% to 3% (the remaining 3% a client-side cookie banner with no semantic weight), the fix detailed in the empty shell audit. Fix 2, schema: a SoftwareApplication block was added to product and pricing pages with name, description, applicationCategory, offers (price, currency, validity), and featureList, plus TechArticle with verified Person authors on blog posts. Re-audit: schema moved 22 → 84, nesting integrity passed, and pricing became machine-readable at the structured-data layer rather than locked in a CSS-styled table. Fix 3, entity clarity: a verified LinkedIn company page and Crunchbase profile were created, both URLs added to the sameAs array, and a Wikidata entry created with founding date, category, and website linked. Re-audit: entity clarity moved 51 → 79, the brand now resolvable with three corroborating references, the entity home pattern. Fix 3b, token efficiency: the homepage <main> was restructured to open with a definitional lede (brand, category, value proposition in the first sentence) before nav and banners, with bundle splitting to cut inline script overhead. Re-audit: token efficiency moved 58 → 76, and the 100-Token Rule passed for the first time.
4. Final Score: 91
Composite score after all four fixes validated: 91, Optimized.
| Signal | Baseline | Post-fix | Delta |
|---|---|---|---|
| Rendering | 14 | 88 | +74 |
| Schema Validity | 22 | 84 | +62 |
| Token Efficiency | 58 | 76 | +18 |
| Entity Clarity | 51 | 79 | +28 |
| Crawl Access | 71 | 74 | +3 |
| Semantic Structure | 66 | 69 | +3 |
| Overall | 38 | 91 | +53 |
Crawl access and semantic structure weren't targeted in this sprint and moved only marginally, the small gains a side effect of the SSR migration improving how crawlers interacted with the page structure; both remain on the roadmap for the next cycle. The full weighting that makes a 91 possible is in the signal scoring guide.
5. Outcome Context
Structural optimization removes the barriers to citation, it doesn't guarantee citation, which depends on content quality and semantic distinctiveness relative to existing sources. What changed immediately after reaching 91: the brand's ChatGPT description updated to the current feature set (the accurate, schema-marked data was finally retrievable), Perplexity began including the product page as a source in category queries, and the brand started appearing in AI-generated comparison articles sourced from the web. What did not change immediately: Share of Model in high-competition queries, because the site was now in the retrieval pool but whether it gets selected depends on content strategy, a separate discipline tracked through Share of Model. The audit-fix-validate loop ran four times over three weeks, with roughly 14 hours of total development time across all fixes.
What would your baseline come back at?
Free audit. Get your per-signal scores, find out which failures are keeping you in the Invisible tier, and see the priority order for fixing them.
Run your baseline audit →The contrarian lesson of a 38-to-91 jump in 14 hours: the gains weren't earned by writing better content, they were earned by deleting the obstacles that hid the content already there. This site ranked on Google the entire time, which is exactly why its owners never suspected a problem, and it's the uncomfortable truth of AEO that the highest-leverage work is almost never creative. It's removing the empty shell, the missing schema, the boilerplate that buried the value proposition, the engineering equivalent of cleaning a window rather than repainting the room. The teams that wait for a content overhaul to fix their AI visibility are repainting; the ones that win are cleaning the glass.
Reference Sources
- Website AI Score Engine: technical specification of the six scoring signals. View article
- Next.js SSR Documentation: getServerSideProps and getStaticProps implementation. nextjs.org/docs
- Schema.org SoftwareApplication: type specification and property definitions. schema.org/SoftwareApplication
- Wikidata: entity creation and external corroboration for brand disambiguation. wikidata.org
- AEO Validation Loop: how to structure fix-and-validate cycles. View article
